Excel pivot tables have been how I have reorganized data…up until now. These are just a couple of examples why R is superior to Excel for reorganizing data:
UPDATE: I fixed the code to use ‘dcast’ instead of ‘cast’. And library(ggplot2) instead of library(plyr) [plyr is called along with ggplot2]. Thanks Bob!
Also, see another post on this topic here.
library(reshape2)
library(ggplot2)
dataset <- data.frame(var1 = rep(c("a","b","c","d","e","f"), each = 4),
var2 = rep(c("level1","level1","level2","level2"), 6),
var3 = rep(c("h","m"), 12), meas = rep(1:12))
Created by Pretty R at inside-R.org
# simply pivot table
dcast(dataset, var1 ~ var2 + var3)
Using meas as value column. Use the value argument to cast to override this choice
var1 level1_h level1_m level2_h level2_m
1 a 1 2 3 4
2 b 5 6 7 8
3 c 9 10 11 12
4 d 1 2 3 4
5 e 5 6 7 8
6 f 9 10 11 12
# mean by var1 and var2
dcast(dataset, var1 ~ var2, mean)
Using meas as value column. Use the value argument to cast to override this choice
var1 level1 level2
1 a 1.5 3.5
2 b 5.5 7.5
3 c 9.5 11.5
4 d 1.5 3.5
5 e 5.5 7.5
6 f 9.5 11.5
# mean by var1 and var3
dcast(dataset, var1 ~ var3, mean)
Using meas as value column. Use the value argument to cast to override this choice
var1 h m
1 a 2 3
2 b 6 7
3 c 10 11
4 d 2 3
5 e 6 7
6 f 10 11
# mean by var1, var2 and var3 (version 1)
dcast(dataset, var1 ~ var2 + var3, mean)
Using meas as value column. Use the value argument to cast to override this choice
var1 level1_h level1_m level2_h level2_m
1 a 1 2 3 4
2 b 5 6 7 8
3 c 9 10 11 12
4 d 1 2 3 4
5 e 5 6 7 8
6 f 9 10 11 12
# mean by var1, var2 and var3 (version 2)
dcast(dataset, var1 + var2 ~ var3, mean)
Using meas as value column. Use the value argument to cast to override this choice
var1 var2 h m
1 a level1 1 2
2 a level2 3 4
3 b level1 5 6
4 b level2 7 8
5 c level1 9 10
6 c level2 11 12
7 d level1 1 2
8 d level2 3 4
9 e level1 5 6
10 e level2 7 8
11 f level1 9 10
12 f level2 11 12
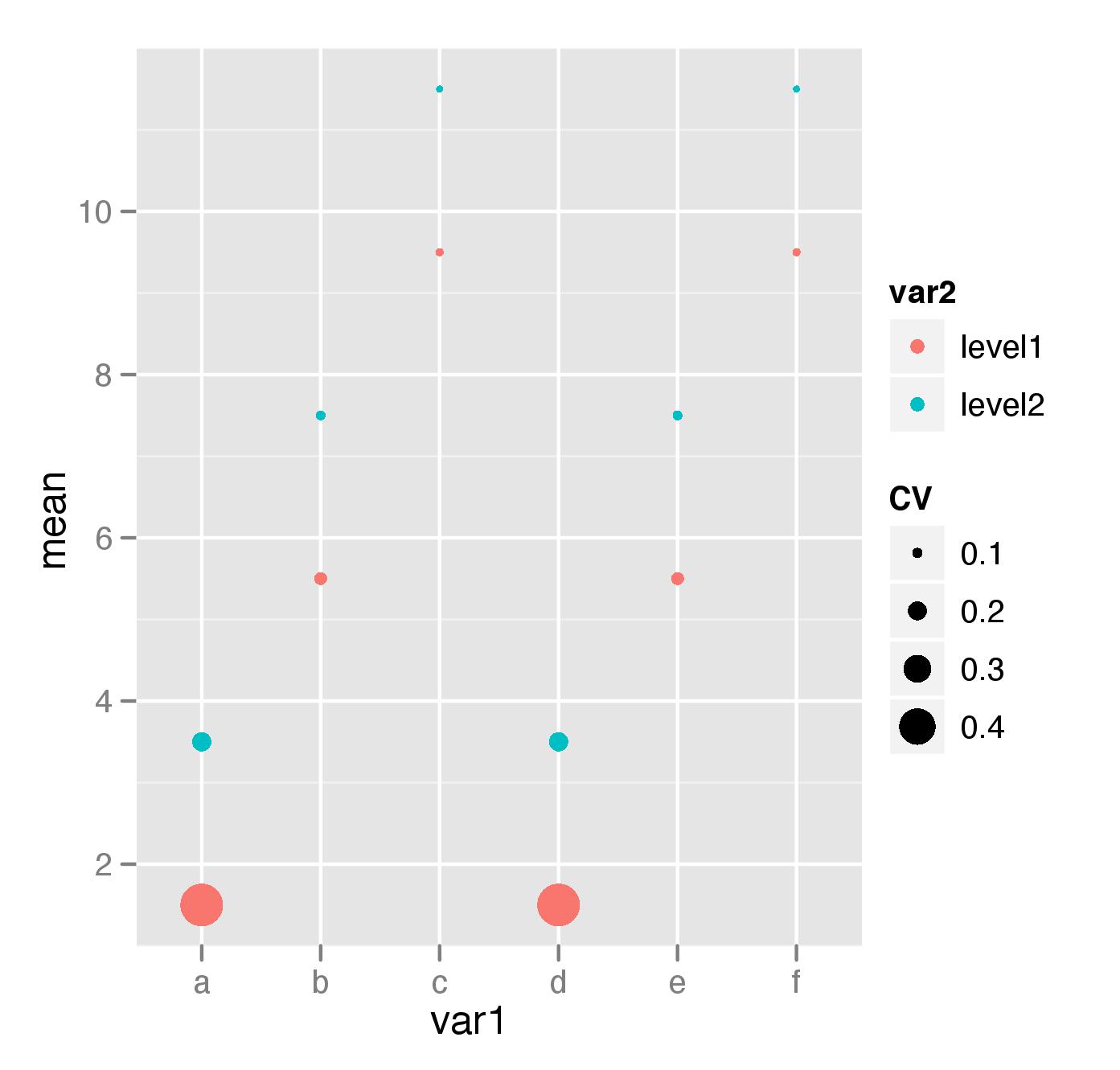
# use package plyr to create flexible data frames...
dataset_plyr <- ddply(dataset, .(var1, var2), summarise,
mean = mean(meas),
se = sd(meas),
CV = sd(meas)/mean(meas)
)
> dataset_plyr
var1 var2 mean se CV
1 a level1 1.5 0.7071068 0.47140452
2 a level2 3.5 0.7071068 0.20203051
3 b level1 5.5 0.7071068 0.12856487
4 b level2 7.5 0.7071068 0.09428090
5 c level1 9.5 0.7071068 0.07443229
6 c level2 11.5 0.7071068 0.06148755
7 d level1 1.5 0.7071068 0.47140452
8 d level2 3.5 0.7071068 0.20203051
9 e level1 5.5 0.7071068 0.12856487
10 e level2 7.5 0.7071068 0.09428090
11 f level1 9.5 0.7071068 0.07443229
12 f level2 11.5 0.7071068 0.06148755
# ...to use for plotting
qplot(var1, mean, colour = var2, size = CV, data = dataset_plyr, geom = "point")